


Mindful Spending: Slashing $500K from Our AWS Bill
Since the economic downturn of 2022, startups must prioritise profitability and sustainable growth and operate more like traditional businesses, focusing on increasing earnings and reducing costs. For a FinTech startup, Cloud spending, a significant recurring expense, grows with scale, making cost-saving crucial in this area
$1 saved monthly will lead to $12 savings annually
FamApp is a fin-tech application enabling seamless UPI & Card payments for the next generation. AWS forms the backbone of our tech stack empowering our application to run at scale for millions of users.
Being a fintech startup with increasing scale and cost, last year we set out to define goals for cloud spending to keep it in check. We started utilising AWS services for spend analytics and taking measures to reduce the ever increasing cost and root out inefficiencies.
In this blog, we will mainly focus on AWS cloud cost, as that’s the biggest recurring tech cost for us. Here majority of the cost comes from Databases, Cache and EC2 servers running stateless backend applications.
How?
What is measured, can be improved — Peter Drucker
With a team of talented engineers, the best way is to define ambitious goals that are objectively measurable.
Non Goal
- Reducing platform reliability by not having redundancy.
- Increasing latency via using cheaper hardware.
Defining Goal
The first question that comes to our mind before we start defining the goal is:
- Where does our revenue come from?
- What makes our revenue scale?
For example, if our user base increases, this will lead to more potential customers entering the top of the funnel, which is likely to result in higher revenue from the goods and services provided on the platform.
Following this approach, we had three ways to link revenue numbers with the scale:
- MAU → Monthly Active Users
- Count of users who opened the app at least once in a month
- MTU → Monthly Transacting Users
- Count of users who did at least one payment in a month
- MT → Monthly Transaction Count
- Total number of successful payments in a month
Here we agreed on → How many users make payment in a month ie. Monthly Transacting Users (MTU) as a factor.
Why MTU ?
How do we create value for the user? When user uses our platform to make payments
If we were to choose MAU as a factor, this would mean there would users using our platform but value creation is not guaranteed there. For the 3rd factor, ie. total transactions, this would result in value creation but cannot guarantee the scale of per user value creation as implied in the Pareto Principle.
The Pareto principle states that for many outcomes, roughly 80% of consequences come from 20% of causes.
Example
Let’s say our AWS cost is $80,000 per month and have 1M MTU. With $1 = 83.9 INR, AWS spends per transacting user would be
Based on unit economics, to have sustainable business, how much can you afford to spend on cloud ? We decided to pursue 1 INR / MTU as our north star metric for cloud cost.
Thus, we need to reduce cost ~85%. Engineers are now looking into business metrics, as the target is directly related to it, enforcing product-minded engineering.
Dissect spends
Strategy - Always start from $0 - what can we do to spend nothing ? Pick up low hanging fruits.
By Engineering Team
- Frontend: ~7% - AWS
- Mobile (Android & iOS: 3% - Firebase
- Backend: 90% - AWS
Note: these are not exact numbers.
Since we’re a Y Combinator funded start up, we tried to utilise investor credits wherever we could.
Making frontend spend come down to $0
- Via migrating to cloudflare pages. Here, technically, we needed to serve only pre-built js, css, html static files.
- Convert Server-Side-Rendering (SSR - Next.js app) → CSR.
- We wanted to skip running node.js server. Moving to static apps made it easy and efficient to deploy.
- We utilised cloudflare workers where server side logic was needed.
Making Mobile spend <1%
Most of the cost came from firebase realtime database, so we opted for a different strategy to serve the same use case. We used this for only basic static config, so it was relatively strait-forward.
Backend
Backend isn’t just backend application cost, it includes security and data analytics cost as well. We consider everything as backend cost. Since this was the biggest pie, we divided this further.
By product feature
- Chat
- Feed
- Transaction
Based on backend API requests per month to serve specific features.
What value are we providing to the user via having this specific feature? How many users would come back asking for the specific feature if it gets removed?
Based on the above, we decided to sunset features that didn’t provide value to the user. This was one of the biggest levers for us and helped us reduce cost by roughly ~30%.
Being a startup, we iterate heavily and over the course of 4 years we accumulated several features that were already sunset. However, from backend, computation required for those was still being done.
We may call this as tech debt. Having feature sunset process would help here, so that when the product team decides to discontinue, the backend team would be aware about changes as it gets added to backlog.
So far we didn’t need to have specific instrumentation in place to be able to reduce spends as these metrics were already available.
By Business unit
We needed a deeper understanding on what exactly we’re spending on, and how much. For this, AWS provides a feature called user defined cost-allocation tags.
What is a tag?
We can assign Key - Value pair to AWS resource.
Name: "backend_api"
// Key = Name
// Value = "backend_api"
Using AWS cost explorer, we can plot graph that shows you cost ($) by Tag_Key
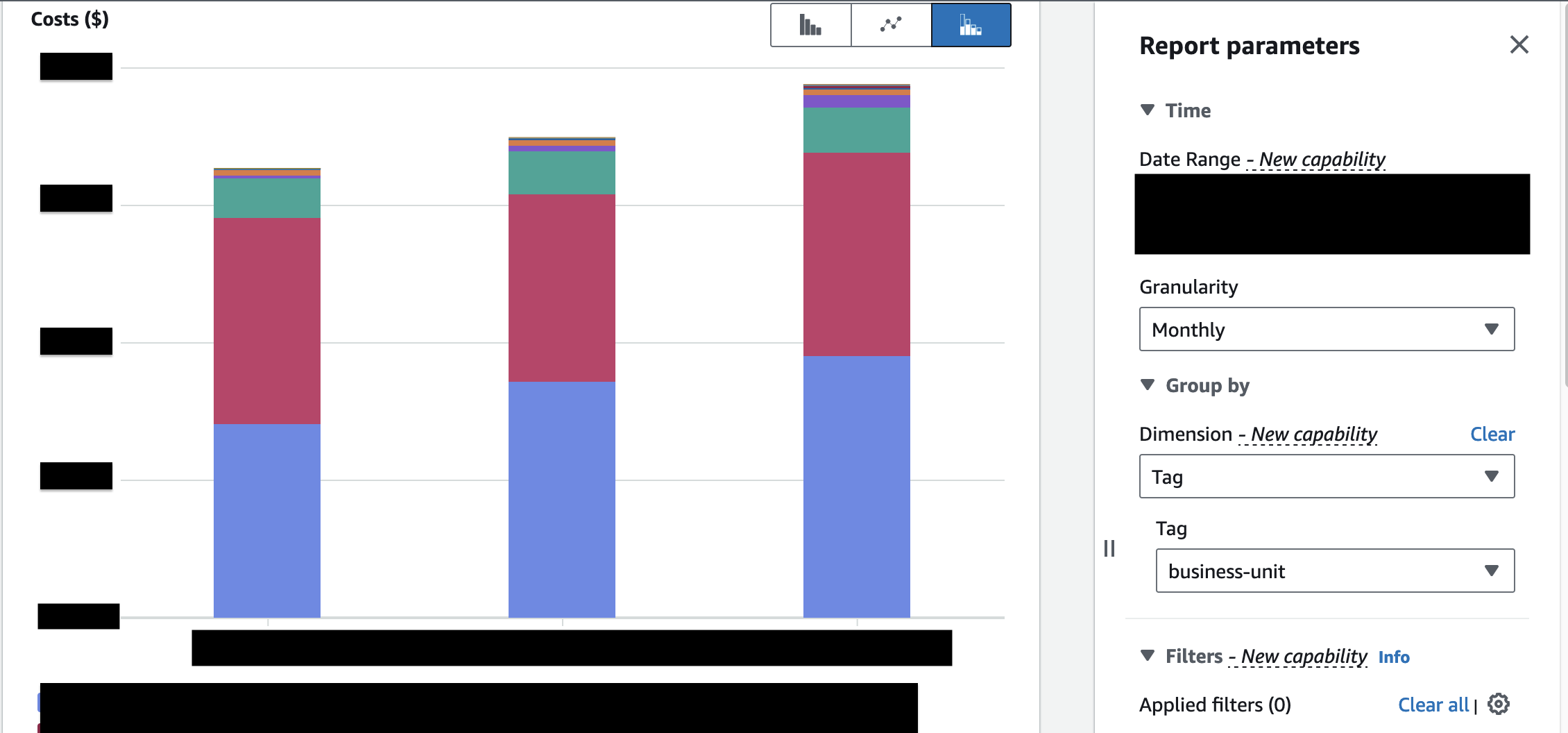
As you may recall from the story behind our tech stack, from the start we bet on infrastructure automation by using pulumi to define cloud infrastructure as code.
This allowed us to instrument existing and new infrastructure with ease. We also concluded to have cost-center and business-unit tag on each resource.
const commonTags = {
"Name": "msk-cluster",
"Environment": curEnvironment,
"cost-center": "CoreEng",
"business-unit": "Engineering"
};
/*
Name => resource name
Environemnt => PROD | STAG
business-unit => Product | FinOps | Support | Risk | Recon | CoreEng
cost-center =>
*/
Define Cost-Center
- For product, services required for given use case to work. Since for given use case we need to touch multiple services, we opted to use
cost-centervalue asservice-name - For common infra where it was not possible to assign direct product function, we use
CoreEngas business unit and use case =loggingas cost center.
Bulk tagging of resources
We built in-house tooling to attach tags in bulk for services that were created directly using console.
-- Store AWS resources
CREATE TABLE IF NOT EXISTS resources (
resource_arn TEXT PRIMARY KEY,
tags_json TEXT,
account_id TEXT,
business_unit TEXT,
cost_center TEXT,
service TEXT,
created_at DATETIME
)
INSERT OR REPLACE INTO resources (
resource_arn, tags_json, account_id, created_at, business_unit, cost_center, service
) VALUES (?, ?, ?, ?, ?, ?, ?)
-- Store rules
SELECT
"rules"."resource_arn" AS "resource_arn",
"rules"."pattern" AS "pattern",
"rules"."business_unit" AS "business_unit",
"rules"."cost_center" AS "cost_center",
"rules"."is_active" AS "is_active"
FROM
"rules"
WHERE
"rules"."is_active" = 1
and ("rules"."account_id" = ? OR account_id is null)
-- Fetch resource
SELECT
"resources"."resource_arn" AS "resource_arn",
"resources"."tags_json" AS "tags_json",
"resources"."created_at" AS "created_at"
FROM
"resources"
WHERE
"resources"."business_unit" = ''
AND (LOWER("resources"."tags_json") LIKE ? OR "resources"."resource_arn" LIKE ?)
AND "resources"."account_id" = ?
Steps:
- Fetch & store all AWS resources in SQLite
- Define rules table which can have regex or specific resource id and value for
cost-centerandbusiness_unit
Go through active rules and apply tags.
for _, r := range rules {
if r.arn != nil {
applyTags(ctx, *r.arn, *r, svc)
} else if r.pattern != nil {
processPattern(db, r, svc)
} else {
log.Warn("rule does not have pattern or arn", "rule", *r)
}
Common Optimisation Areas
- Optimising Cloudfront and Load Balancers
- We saw a 99% reduction in cost by utilising cloudflare edge caching with cache hit ratio of 99.5%
- Utilised Cloudflare R2 for common public assets. Here, add aggressive edge caching policy and make resources immutable.
- Instance Volume Type and AMD Instances
- Use
c6a,m6a- AMD instances - Use
gp3volume for all instances and RDS storage type, instead of provisioned IOPS (io2) - Use spot instances when you can, if not commit minimum compute spends to get discount. Use reservation and saving plan tab in cost explorer for suggestions.
- Use
- Inter-AZ Communication
- Understanding of data transfer costs between Availability Zones. You can utilise cost-explorer here.
- Keeping majority of the instances in the same zone as primary db and cache nodes
- Hibernation of Development Servers: We were able to reduce spend by 80%. We plan to write about this in detail in the future, stay tuned!
- In micro service environment for testing, we launch all the dependant services for each feature
- Automatically stopping servers when unused via using request logs did wonders. The learning here is to automate when you can.
- Here hibernated servers become live within 5 mins when someone tries to use the endpoint.
- Utilise postgres logical database to have one server for all micro-services in development environment.
- In micro service environment for testing, we launch all the dependant services for each feature
- RDS Snapshots and EC2 Volumes
- Remove unattached unused volumes in EC2.
- Archive older snapshots - RDS snapshot cost is ~100$ per TB
- S3 Objects
- Setup data archiving policy
- In case you have versioning enabled and deleted objects, they’ll use storage space.
- Setup deletion policy for older transient data
- Effective Use of Karpenter
- For EKS cluster, we strongly recommend to use karpenter and utilise spot instances and compact pod packing
- When pods have CNI attached to use AWS IAM roles for pods, there is a limit on instance, how many CNI can be attached which would cause node to stay underutilised.
- Increase pod cpu / ram requests to use bigger pod which would handle more requests. Eg. running 10 smaller pod would cost more than 3 big pods with equivalent compute capacity due to limit of CNI - container network interface
- Rightsizing Container Resources & Ec2 Instances
- Use opensource tooling like kubecost to analyse effectiveness
- Compare workload wrt instance type. Eg. using c6a.large vs t3a.medium, by calculating count of instance * instance_type to run same workload.
Process
- Bi-weekly calls to analyse spend data and impact of optimisation
- Monthly update with INR cost per MTU with team
- Cost analysis as part of technical review document when building new features
Future plans
- Make tagging mandatory / 100% cost allocation tag coverage
- Automatic detection on cost anomaly and alerting
Conclusion
- Define goals based on business metrics, instrument resources, and regularly look at spendings.
- Experiment with various options, keep iterating and analyse impact.
- Automate, automate, automate.


